EOPAS - EthnoER online presentation and annotation system
Sharing access and analytical tools for ethnographic digital media using high speed networks
Preparation of an open-source streaming server with time-aligned text: towards a distributed international language museum using EOPAS, the EthnoER online presentation and annotation system.
Chief investigators
Assoc. Professor Nick Thieberger, Professor Rachel Nordlinger, Cathy Falk (Music, the University of Melbourne), Steven Bird (Computer Science and Software Engineering, the University of Melbourne), Linda Barwick (PARADISEC, University of Sydney)
Grant type
Current (2013) research and development under ARC DP0984419
ARC Special Research Initiatives E-Research (2005-2006)
Please note: that the media will only work in HTML5-compliant browsers, Chrome or Firefox
The new EOPAS is now ready. Please see the Using the EOPAS system web page for details on how to use EOPAS and the file format requirements. A working version of the new EOPAS system can be seen at EOPAS website and an example using video can be seen on the Audio Annotations web page.
Here you will find two short videos, the first of which describes how to use EOPAS and the second of which describes how to get your own material online in an EOPAS format. (note that these files use the same server as all EOPAS files, and require only that your browser is HTML-5 compliant)
Using EOPAS
Original plans
This project provides an open-source framework for delivery of media in an application addressing the problem of how to make language data more generally available than it currently is. While the content of the media to be delivered is scholarly research, the method employed is one that is already being developed for significant data sets elsewhere in the world (eg Metavid), and the users are likely to be both scholars and the general community who have an interest in the diversity of the world's languages. With the development of HTML5 and the availability of the free and open-source media server Annodex, we are seeing the possible uses of broadband-enabled media (audio and video) increase exponentially. This pilot project will first build an open-source installation with the aim of later creating an online network of language collections linking transcripts and media, based in the existing international network of digital language archives and leveraging their collections as the basis for a networked virtual museum of human languages. The textual system on which this is all based, called EOPAS and developed in 2006 under an ARC eResearch grant, has been well received in presentations here and in the USA and the UK. The present project will redevelop this system to take advantage of recent developments in technology.
This type of scripting can be used to call the media for lexical citation forms played from a single media file or for arbitrarily long lines of text showing a continuous text called from a single media file.
We have set out a series of milestones over 2010 to rebuild the media upload and transcoding module and the text upload and presentation system. There is an open-source and documented system on Sourceforge. The EOPAS development site has mailing lists to keep interested people up to date with the project. If you want to subscribe they will be very low traffic lists, one for announcements and one for developers.
Programming will be provided by Silvia Pfeiffer and John Ferlito, CEOs of Vquence and creators of and specialists in the use of Annodex, who will also install the database used in the project. Silvia Pfeiffer has been actively involved in the development of current Web video technologies, she is an invited expert on the W3C HTML, Media Annotations, Media Fragments, and Timed Text working groups and is actively shaping future video standards and technologies.
Her company developed Vquence (Dr Sylvia Pfeiffer CV on Ginger Tecnologies website)
Goals of the present project
- Updating of EOPAS from an eXist XML database with associated systems (as described in Schroeter and Thieberger 2006) to an extensible DB structure to allow upload, validation, browse and playback of text and media. Provision of citability to utterance level, and licensing of uploaded material (using CC-licences)
EOPAS requirements
- login functionality: authenticated access to upload/edit/download
- upload functionality of video/audio
- transcoding video/audio to Ogg Vorbis and Ogg Theora formats for delivery, with an option to move to WebM by the end of 2010
- storage of video/audio
- download video/audio
- upload functionality of text (ELAN, Transcriber, IGT from Toolbox)
- handling of unicode and other i18n characters
- validation of text
- transcoding text
- storage of text
- download text in different formats (ELAN, pdf, rtf)
- aligned display of text with video/audio
- search
- citability on the level of syllables linked to video/audio (standard media fragment URIs)
- editing (but not authoring!) of text
- open source publication of system
- creation of project in Sourceforge
- Development of an access module to allow only authenticated users to access data streams.
- Documentation of the process of installation, and the workflow required to prepare data for upload into both the media server and EOPAS
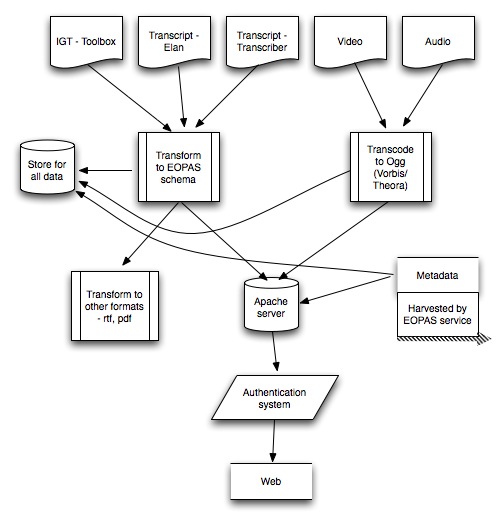
A schematic view of the process involved in converting fieldwork recordings and transcripts into online text and media is given below:
The project was originally funded by the Institute for a Broadband-Enabled Society (IBES) which became the former Melbourne Interdisciplinary Research Institutes, Networked Society Institute.
Chief Investigators: Nick Thieberger, Linguistics, the University of Melbourne; Rachel Nordlinger, Linguistics, the University of Melbourne; Cathy Falk, Music, the University of Melbourne; Steven Bird, Computer Science and Software Engineering, the University of Melbourne; Linda Barwick, PARADISEC, University of Sydney.